PROGRAMAS Y LENGUAJES DE PROGRAMACIÓN.

¿Cómo es un programa?
Veamos uno:
#include<stdio.h>
/*
Este programa muestra el número de argumentos
que se le han proporcionado a través de la línea de órdenes.
*/
int main(int argc, char * argv[])
{
printf("El número de argumentos de este programa es %d\n", argc);
return 0;
}
El texto que se ve sobre estas líneas se escribe con un editor de texto y se almacena en un archivo de texto (por ejemplo,
prueba.c
). En nada se diferencia este programa de cualquier otro documento de texto que podamos crear, e s un documento de texto estándar. Su contenido está escrito siguiendo las reglas de sintáxis de un lenguaje de programación (q.v.) concreto, que en este caso es
C
. En este text o se pueden apreciar tres partes:
-
Una primer línea en la que aparce una directriz de compilación (
include
). Esta línea va a estar presente en la práctica totalidad de los programas que escribiremos, salvo que se trate de funciones que no lean inf ormación de teclado y no muestren información en pantalla. Apréndasela de memoria:
#include<stdio.h>
. Si tiene un sistema basado en Unix (como Linux o Macintosh), saque una terminal y teclee
man stdio
. No se asuste.
-
Un comentario (el texto que va desde
/*
hasta
*/
). Este comentario no forma parte del programa; de hecho, es ignorado por el compilador. Sin embargo es de gran ayuda para los programadores, que dejan notas para sí mismos y para otros programadores que deban leer o modificar el código en el futuro. Apréndalo de memoria: un comentario empieza con
/*
y sigue hasta llegar a un
*/
. Posiblemente el editor que utilice cambiará el color del texto correspondiente a los comentarios. Véanse los ejemplos de las próximas imágenes.
-
Una función, que en este caso se llama
main
. La función tiene dos partes: el encabezado, que es la primera línea (desde
int
hasta el paréntesis de cierre), y el cuerpo o bloque de la función, que barca desde la llave de apertura (
{
) hasta la llave de cierre (
}
).
Ya ve, no era tan difícil. El aspecto que presenta este programa, copiado de la página web y pegado en un editor de textos es el que puede verse acto seguido.
|
|
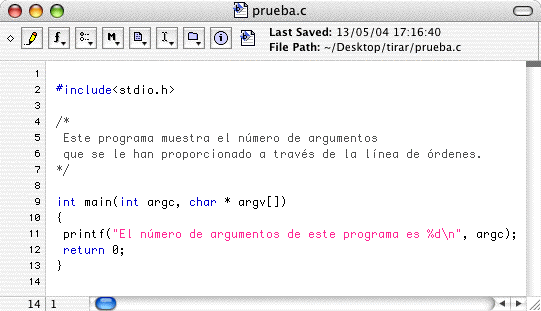
Este es el programa anterior visualizado con
BBEdit
. Obsérvese que los comentarios están en color distinto al del código fuente. Las cadenas de caracteres (el texto que va entre comillas, " y ") también poseen su propio color.
|
|
|
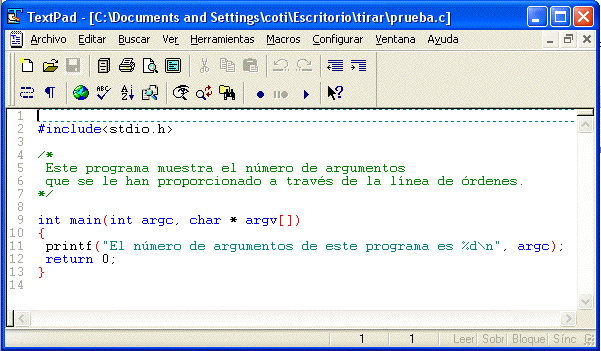
Este es el programa anterior visualizado con
TextPad
. Obsérvese que los comentarios es tán en color distinto al del código fuente. Las cadenas de caracteres (el texto que va entre comillas, " y ") también poseen su propio color.
|
Nuestro objetivo es conseguir que el ordenador ejecute este programa. Para ello, será preciso traducir este texto, escrito por nosotros, a un formato admisible para el ordenador; después habrá que ejecutar el programa. Siga le yendo.
Datos y estructuras de datos
Sin más que examinar el programa anterior, se observa la existencia de datos en el mismo; concretamente, el dato
argc
(
argument count
o contador de argumentos) se va a imprimir (
print
) en la pantalla. La palab ra
int
alude al tipo de datos (integer o entero) que estamos manejando, e indica al compilador (el programa traductor) cómo se debe codificar el argumento
argc
. Internamente, toda la información que maneja el ordena dor se representa mediante números codificados en binario, pero existen distintos tipos de codificación. Una letra, un número entero y un número real no tienen la misma codificación interna. Se llama tipo de datos a cada una de estas codificaciones.
Una estructura de datos es una colección de datos, cada cual con su propio tipo o codificación. Para obtener un procesamiento eficiente, es preciso utilizar unas estructuras de datos cuidadosamente diseñadas. El lector interesado hallará en [
1
] una notable cantidad de información relativa a estructuras de datos. En cuanto a los métodos empleados para el procesamiento de la información contenida en estas estructuras (a lgoritmos), véase [
2
].
Algoritmos, programas y flujo de control.
Un algoritmo es un procedimiento para llevar a cabo una tarea. Para ser exactos, un algoritmo es un conjunto finito de reglas que permiten obtener una sucesión finita de operaciones que sirven para resolver un cierto problema. Para que un procedimi ento pueda recibir el nombre de algoritmo, tiene que posee las cinco propiedades que detallamos a continuación:
-
Es finito. El algoritmo tiene que concluir al cabo de un número finito de pasos. Este número podría ser tan elevado como se quiera, pero tiene que ser finito, y por ende realizable en una cantidad finita de tiempo.
-
Todos los pasos están definidos. Todas las operaciones del algoritmo tienen que estar definidos de forma precisa; esto es, las acciones que se deben realizar tienen que estar especificadas sin ambigüedad en todos los casos.
-
Tiene entradas o datos. Todo algoritmo debe poseer una o más entradas o cantidades que se le proporcionan inicialmente, antes de empezar, o de forma dinámica durante su ejecución.
-
Produce salidas o resultados. El algoritmo debe producir uno o más resultados, que tendrán una relación específica con las entradas.
-
Es realizable. Esto significa que todas las operaciones deben ser suficientemente sencillas para que una persona pudiera realizarlas con papel y lápiz en un periodo finito de tiempo.
El lector interesado hallará
aquí
la página personal del Prof. Donald Knuth, autor de la definición anterior. Su contribución al desarrollo de la Informátic a en general, y de los algoritmos en particular, solo puede calificarse de monumental. Su obra "The Art of Computer Programming" debería formar parte de la biblioteca de cualquier persona interesada en temas relacionados con la Informática.
Un programa es la implementación o realización de un algoritmo en un determinado lenguaje de programación.
Los programas están formados por fragmentos individuales de código, que se denominan sentencias. En el programa examinado,
print(...);
es una sentencia. Estos fragmentos, que representan operaciones del algoritmo ejecutado, se v an ejecutando en el orden correcto para aplicar el algoritmo, y el orden puede ser de varios tipos:
-
Secuencial. Se ejecuta una secuencia de instrucciones respetando siempre un mismo orden, sin variaciones.
-
Alternativo. Se ejecuta una u otra instrucción (de entre dos) en función de las necesidades del algoritmo. El orden de ejecución depende de las entradas o resultados intermedios del algoritmo.
-
Selectivo. Se ejecuta una u otra instrucción (de entre varias) en función de las necesidades del algoritmo. El orden de ejecución depende de las entradas o resultados intermedios del algoritmo.
-
Repetitivo. Un bloque formado por una o más sentencias se ejecuta varias veces, dependiendo del estado del algoritmo en ese momento. El número de veces que se ejecuta el bloque puede ser fijo, y también puede depender de las entrada s del algoritmo.
Por así decir, las sentencias se ceden entre sí el control de la ejecución. En el caso secuencial, cada sentencia cede el control a la siguiente. En el caso alternativo, se utiliza una estructura de control (una clase especial de sent encia) que determina la ejecución de uno u otro bloque de código. En el caso selectivo, la estructura selectiva determina el bloque ejecutado en función del valor de una expresión de control. Y en el caso repetitivo, la estruct ura repetitiva determina si se produce o no la iteración en función de una expresión de control. Cada lenguaje de programación posee una sintaxis propia para estructuras de control; véase por ejemplo el caso de
C
.
Codificación binaria de la información
Las computadoras procesan únicamente información de formato binario. Toda la información procesada por la computadora (texto, números, sonido, imágenes, video) se reduce a ese formato. Los periféricos efectúan la traducción de información entre el mundo real y la computadora. La información binaria que procesa la computadora es una representación de la información real; es necesario imponer unas reglas de equivalencia entr e información real e información binaria, que se denominan tipos de datos. Un tipo de datos es una convención para la codificación de información; evidentemente, se especifica tanto el procedimiento que convierte información "humana" en binario como el que produce información comprensible para seres humanos a partir del formato binario.
Lenguaje Máquina
Un procesador actual es un descendiente muy sofisticado de los primeros circuitos integrados. En ellos, se implementaban unos pocos elementos lógicos, capaces de realizar operaciones como AND, OR, XOR, NOT, etc. Con el paso del tiempo, se pens&oacu te; en construir varios circuitos lógicos en un sólo circuito integrado, de tal modo que el usuario pudiera seleccionar arbitrariamente la función que desempeñaría el circuito en cada momento. Esto es, al activar un cierto hilo de control, el ciruito realizaba (por ejemplo) la conjunción o AND de sus entradas, proporcionando el resultado correspondiente. Pero al cambiar el hilo de control sometido a tensión, se activaba el circuito OR (por ejemplo), produci éndose entonces la disyunción lógica de las entradas. De este modo, en el circuito había unos hilos de datos, otros de control, y otros de resultados.
Inicialmente, la programación en lenguaje "máquina" se efectuaba escribiendo directamente instrucciones formadas por unos y ceros; las instrucciones se almacenaban en un sistema de memoria para después ser ejecutadas. Esto resultaba difícil, y pronto se desarrolló lo que hoy en día suele denominarse "lenguaje ensamblador"; en un principio no era otra cosa que una colección de nombres fáciles de recordar (códigos mnemotécnicos) que eran sustituidos por sus equivalente binarios mediante un programa, el ensamblador. La tarea seguía siendo lenta y difícil.
Es importante que cada fabricante ofrece un conjunto de circuitos diferente en sus procesadores, que por tanto tendrán distintas capacidades (distintos conjuntos de instrucciones, según se dice en la jerga informática). Lo que es peor , la colección de tensiones (la instrucción) que sirve para activar una cierta operación en distintos procesadores va a ser distinta en general. Esto implica que un mismo conjunto de instrucciones va a producir resultados diferentes y normalmente sin sentido en distintos procesadores: el fenómeno se conoce con el nombre de incompatibilidad de instrucciones.
Esta situación resultaba insostenible, porque obligaba a reescribir todos los programas cada vez que cambiaba el procesador, lo cual era frecuente para añadir mejoras, mejorar el rendimiento, etc. Lo deseable era algún procedimiento q ue permitiera mantener el texto del programa al cambiar de procesador. Esto exigía, desde luego, un procedimiento de traducción a lenguaje máquina mucho más sofisticado, en el cual el programa traductor conociera el procesador de destino y fuera capaz de generar código máquina para él, partiendo de un lenguaje independiente del procesador.
Lenguajes de alto y bajo nivel
Se creó entonces un nuevo tipo de lenguajes, denominados "lenguajes de alto nivel", que poseían dos características importantes:
-
Cada instrucción de alto nivel se traducía a múltiples instrucciones en lenguaje máquina, posiblemente centenares o incluso miles. Los lenguajes de alto nivel suponían uno enorme ahorro de tiempo para los programadores , al ofrecerles instrucciones que llevaban a cabo tareas similares a las que se realizarian con papel y lápiz.
-
Las instrucciones de los lenguajes de alto nivel eran completamente independientes del procesador empleado para ejecutar el código máquina correspondiente. La traducción a lenguaje máquina, necesariamente más compleja, suponía un mayor esfuerzo al crear el programa traductor, pero aportaba la ventaja de no tener que reescribir todo el código al ejecutar el programa en otro procesador.
Una desventaja de los programas de alto nivel era su menor eficiencia, al ser prácticamente imposible crear un traductor que generase un código máquina tan eficiente como el que escribiría un operador humano experimentado. Sin embargo, la velocidad creciente de las máquinas y los prohibitivos costes de producción del software aconsejaban el uso de lenguajes de alto nivel, y esto es precisamente lo que sucede en la actualidad. El uso del código ensamblador e stá reservado a las rutinas críticas en términos de espacio o tiempo, y resulta innecesario en múltiples ocasiones.
Intérpretes y compiladores
Inicialmente, la cantidad de memoria de que disponían los ordenadores era muy reducida, debido al elevado coste de fabricación de los circuitos de memoria. Esto suponía fuertes limitaciones a la hora de construir programas traductores de alto nivel, que no podían manejar grandes cantidades de información simultáneamente, almacenándola en memoria.
Por esta razón, se optó inicialmente por la construcción de los denominados "lenguajes interpretados". Un lenguaje interpretado suele ser un lenguaje de alto nivel, con una peculiaridad: se traduce a código máquina por l íneas individuales; el código máquina de cada línea se ejecuta al momento (sin esperar a que se traduzcan las líneas posteriores)... y se descarta. Si, se descarta, con objeto de no aumentar el consumo de memoria que sup ondría almacenarlo. Después se toma otra línea de programa, se compila (esto es, se traduce a código máquina), se ejecuta esa línea, y se descarta también. De este modo, el consumo de memoria es realmente r educido, y casi independiente de la extensión del programa, esto es, del número de líneas de que conste. Sólo se mantienen en memoria los datos que maneje el programa, no las instrucciones que se aplican a esos datos. Los lengu ajes basados en un intérprete tienen una desventaja notable en lo tocante a velocidad de ejecución, debido a que es preciso traducir cada línea a código máquina siempre que se ejecuta esa línea. Si una misma l&iac ute;nea se ejecuta mil veces, será preciso traducirla mil veces, y esto supone una cantidad de tiempo muy importante.
Por esta razón, la bajada de precios de la memoria RAM dio lugar a la aparición de otro tipo de lenguajes, los "lenguajes compilados". Un compilador es un programa traductor, que al igual que un ensamblador o un intérprete admite un p rograma y lo traduce a instrucciones en código máquina, ejecutables en el procesador. Además, los compiladores llevan a cabo un proceso de optimización con objeto de producir un código máquina de calidad similar a la que produciría un operador humano; por ejemplo, reordenan las instrucciones del programa o las modifican con objeto de lograr que el código final sea lo más eficiente posible. A diferencia de los intérpretes, los compilador es almacenan la totalidad del código traducido en memoria y almacenan en disco una imagen del programa adecuada para su posterior ejecución. Se invierte un cierto tiempo en el proceso, pero el resultado es un código que se ejecuta muc ho más deprisa que en el caso de un intérprete, al no requerir el paso de traducción previo a la ejecución de cada línea de código.
Proceso de compilación
El proceso de generación de un ejecutable tiene en realidad varios pasos:
-
Compilación.- Consiste en traducir el programa fuente (q.v.) a instrucciones de código máquina. El lenguaje de programación hará uso de rutinas creadas previamente, que se tomarán de la biblioteca del lenguaje. Por tanto, el código objeto que se produce como resultado de la compilación contiene tanto código máquina ejecutable como llamadas a rutinas que se añadirán posteriormente.
-
Optimización de código (opcional).- Una vez que se dispone de todo el programa ya traducido a código máquina, se pueden efectuar modificaciones y reducciones que darán lugar a una ejecución más ráp ida sin alterar el algoritmo definido por el programador. Este paso es costoso en términos de tiempo de compilación y puede producir programas más rápidos y voluminosos, o más pequeños a costa reducir la velocidad de ejecución. El lector interesado hallará en la obra "
Construcción de Software Orientado a Objetos
", escriba por B. Meyer y traducida al Español por el que suscrib e, amplia información sobre el fascinante problema de la calidad del softare.
-
Enlazado.- Es el proceso de adición de código perteneciente a bibliotecas (rutinas que ofrece la biblioteca del lenguaje, basadas en los servicios del sistema operativo subyacente). Se trata de las rutinas invocadas desde el programa const ruido por el usuario, que ya existen en el lenguaje y no son producidas por el compilador, al estar prepardadas de antemano.
-
Optimización de código enlazado (opcional).- Es una fasae destinada a eliminar del ejecutable final aquellos fragmentos de código que no se utilicen realmente. De este modo se consigue una imagen más pequeña, lo cual d a lugar a un programa de carga más rápida y que consume menos recursos del sistema (RAM y espacio en disco).
Sólo se ha descrito el proceso de generación de código ejecutable, pero esta no es toda la historia. En una aplicación real, el programador debe contar con imágenes, sonidos, cursores y recursos de diferentes tipos, que sirven para dar al programa sus capacidades diferenciales. Todos estos recursos han de ser creados y almacenados adecuadamente; de hecho, en algunos sistemas operativos avanzados las aplicaciones son realmente directorios con estructura compleja, en los q ue el código ejecutable es tan solo una parte de la aplicación total.
Código Fuente
Es lo que escribe el programador. Para su construcción se emplea un editor de textos ([
3
], [
4
]); normalmente se empleará un formato de texto, aunque algunos entornos efectú an una precompilación y permiten emplear el formato .rtf, lo cual da lugar a una presentacion muy agradable [
5
]. Es frecuente encontrar editores de código fuente que prestan su apoyo automáticamente, dando formato al texto del programa y coloreando las palabras reservadas; en algunos casos, ofrecen también la posibilidad de mostrar los nombres de métodos o clases de la biblioteca del lenguaje. En todo caso, el código fuente es la pieza clave de un programa, porque es la realización o implementación de una colección de algoritmos que especifican el comportamiento de la aplicación creada.
El código fuente debe escribirse teniendo siempre en cuenta que deberá ser mantenido, esto es, que deberá experimentar modificaciones posteriores a su creación. Con gran frecuencia, las modificaciones (reparaciones o adiciones) se producen al cabo de cierto tiempo, y ni siquiera las efectúa el creador de ese código. Por tanto, es esencial crear un código fuente "limpio" (comprensible) y cuidadosamente comentado. La documentación interna (los comentar ios) debe indicar las razones por las que se ha seleccionado precisamente una implementación y non otra. Imagine siempre que debe modificar el programa... y que no lo hubiera escrito. ¿Qué necesitaría saber para poder efectuar modificaciones de forma sencilla, aprovechando el código (sin rehacerlo) y sin introducir errores? Éso es lo que debe indicarse en los comentarios del programa.
La importancia de la documentación es tan grande que algunos lenguajes (notablemente Java) ofrecen una herramienta adicional que permite generar la documentación del programa en HTML a partir de comentarios de formato especial introducidos p or el programador. Véase, por ejemplo, [
6
]
Código Ejecutable
Es el resultado final de nuestros esfuerzos, la aplicación lista para ser ejecutada (y vendida, no lo olvide). Un código ejecutable es un fichero que será cargado en memoria principal y ejecutado; es muy posible que tenga archivos aso ciados, con información adicional, que deberán ser leídos para configurar correctamente la aplicación.
Cuando el usuario solicita la ejecución de un programa, el sistema operativo busca una zona libre de memoria, copia en ella el contenido del archivo ejecutable (que por eso recibe el nombre de imagen binaria) y añade a la lista de procesos e n ejecución uno nuevo, el asociado al programa. Comienza entonces la ejecución propiamente dicha; es frecuente que el programa solicite la carga de nuevos bloques de código (bibliotecas de carga dinámica) que precise para dispo ner de toda su funcionalidad. Para que un programa pueda ejecutarse, debe residir en RAM; cuanto menor sea el espacio ocupado por el programa, más rápida será su carga, mayor será la cantidad de RAM disponible y mayor ser&aacut e; el número de programas que se puedan ejecutar simultáneamente.
Los códigos ejecutables de calidad profesional consideran desde un principio la posibilidad de localización (traducción a otros idiomas), facilitando todo lo posible esta tarea para alcanzar un mercado más amplio.
Concepto de Entorno Integrado de Desarrollo
Visto lo anterior, se aprecia que el proceso de creación de un código ejecutable, resultado final de nuestro trabajo, exige varios pasos previos. Será preciso contar con los programas que se indican a continuación:
-
Un editor de textos especializado en la generación de programas que preste su apoyo para la creación del código fuente y nos permita localizar fácilmente ciertas partes del código, efectuar búsquedas y modificac iones, etc. etc.
-
Un compilador adecuado para el lenguaje en que se vaya a efectuar el desarrollo.
-
Un enlazador (link), compatible con el formato de código objeto producido por el compilador, y que es el encargado de generar el código ejecutable final.
En los primeros tiempos de la informática, era casi habitual emplear un editor de textos de uso general (no especializado), un compilador de algún fabricante y un enlazador de otro, sin que éstos programas hubieran sido diseñad os sabiendo que se iban a utilizar de forma secuencial. Por tanto, era preciso efectuar un proceso como el siguiente:
-
entrar en el editor
-
realizar modificaciones
-
salir del editor
-
entrar en el compilador, intentar compilar
-
salir del compilador
-
volver al editor para corregir errores
-
recompilar
-
salir
-
entrar en editor
-
modificar
-
compilar, etc.
hasta llegar a una ejecución del enlazador que no diera problemas. El código ejecutable generado era, en general, incorrecto, y volvía a empezar el ciclo. Esta inacabable sucesión de entradas y salidas suponía mucho tiem po y esfuerzo.
Afortunadamente, el advenimiento de sistemas operativos multitarea permitía tener el editor de textos abierto en todo momento, en otra terminal, pero nada más... seguía siendo imprescindible acceder a compilador y al enlazador por sep arado. En estas circunstancias surgió el concepto de
Entorno Integrado de Desarrollo
, que se verá en la literatura con las siglas IDE (Integrated Development Environment) o EID. Se trata de un programa matriz que contiene como mínimo un editor, un compilador y un enlazador (y posiblemente un depurador). El objetivo perseguido es que no haya que salir del editor para realizar compilaciones, enlazados y ejecuciones del código ejecutable resultante. De este modo se gana mucho en tiempo y en comodidad; este es el método de trabajo que se emplea normalmente en la actualidad. La lista de entornos de desarrollo es inacabable; véanse, por ejemplo, los siguientes:
Productos Gratuitos
Productos Comerciales
Esta lista no es ni mucho menos exhaustiva; el número de IDE disponibles en la actualidad sumamente elevado. Una búsqueda en Internet revelará un sinfin de posibiliades; el autor utiliza normalmente herramientas GNU en su versión para Mac OS X, así como Project Builder y XCode.
Depurador
 Existe un aditamento habitual de los entornos integrados de desarrollo, que no hemos mencionado hasta el momento. Se trata de un programa o módulo denominado depurador (
Existe un aditamento habitual de los entornos integrados de desarrollo, que no hemos mencionado hasta el momento. Se trata de un programa o módulo denominado depurador (
debugger
debug
en Inglés), que tiene como misión facilitar la detección y corrección de errores en nuestros programas.
Este programa puede ser independien- te, como un editor o compilador, y también puede estar integrado en el sistema de desarrollo, lo cual resulta bastante más cómodo. El uso de un depurador puede volverse complejo si el programa estudiado lo es, pero en principio no requier e grandes esfuerzos por parte del usuario, y resulta ser, con mucho, el método más rápido y cómodo para detectar posibles errores.
De hecho, en un primer estudio de un lenguaje de programación, el conoci miento del editor de textos es tan importante como el conocimiento del depurador
.
La correción de errores es un proceso lento y dificultoso, tanto más cuanto mayor sea la extensión y complejidad del programa. Brevemente, los programas pueden contener errores de dos tipos:
-
Sintácticos. Se deben a una utilización incorrecta del lenguaje de programación empleado. Estos errores suelen ser detectados por el propio compilador, que los señala y da una idea aproximada de la causa del error.
-
Lógicos. También es posible construir programas sintácticamente correctos, admisibles para el compilador y el enlazador, pero que contienen errores debidos al algoritmo o a su implementación. Dan lugar a que el programa no realice sus tareas en la forma deseada, o incluso a la aparición de un error fatal que fuerce al programa a concluir de inmediato. El compilador y el enlazador no pueden detectarlos
El depurador permite ejecutar el programa línea por línea, examinando y modificando el contenido de las variables del programa mientras éste se ejecuta. Por tanto, el depurador facilita mucho nuestra tarea de detección de errores y de sus causas, que podremos corregir una vez conocidas. Los depuradores actuales, integrados con el editor y el compilador, toman información específica que se produce mediante un modo adecuado de compilación y enlazado. El código ejecutable que contiene información para la depuración no es adecuado para su publicación final, esto es, no será el código entregado finalmente al cliente, por cuanto es más lento y voluminoso que el código que produciría normalmente el compilador. Por tanto, suele construirse una versión "de desarrollo" que contiene gran cantidad de información de depuración. Una vez corregidos los errores aparentes, se compila de nuevo el programa en un modo "de producción"; luego se ejecuta y se buscan nuevos errores, que cor regiremos con ayuda de una versión de depuración, y así sucesivamente hasta llegar a una versión (sin información de depuración) que no parezca contener errores. Ésa versión, que suele denominarse GM (Golden Master), será la que entreguemos para su duplicación, y la que llegará finalmente a nuestros clientes como versión 1.0 de nuestro programa.