ARCHIVOS: FORMATO BINARIO HOMOGÉNEO
 Introducción.
Introducción.
La noción de archivo binario homogéneo es la de una colección de registros idénticos, correspondientes quizá a una lista de estructuras de datos que reside en memoria. Normalmente, el modo de apertura será el "r+", para así poder leer o escribir indistintamente. Téngase en cuenta que el lugar del archivo en que se lee o escribe queda por completo en nuestras manos, y que nada (salvo nuestro uso cuidadoso del contador de archivo) garantiza que la posición tenga sentido. Una vez hecha esta consideración, la utilización de "unidades" (los registros) hace posible tratar el disco de manera muy cómoda: la función
fseek()
permite especificar el registro deseado, y las funciones
fread()
y
fwrite()
sirven para leer o escribir. Si se desea ampliar el archivo, nada más fácil que situarnos al final del mismo mediante una llamada de la forma
fseek(fp, 0L, SEEK_END);
para situarnos en esta posición; una llamada posterior a
fwrite()
hará que nuestro archivo crezca adecuadamente. Por último, la llamada a
fclose()
garantizará el correcto almacenamiento de información en el archivo.
Resulta evidente la buena adecuación existente entre las operaciones mencionadas y las propias de una base de datos (altas, bajas, informes y modificaciones). Por tanto, vamos a desarrollar distintos programas que realicen este tipo de operaciones, para así comprender el manejo de archivos binarios homogéneos.
Ejercicio
.- Crear una base de datos de formato binario, formada por registros homogéneos basados en la siguiente estructura:
struct Registro {
char modelo[10];
int fecha;
char fabricante[20];
float peso;
};
La base de datos debe contener información real, legible posteriormente.
Altas
.
El concepto de alta es el de insertar un registro en una base de datos. Este registro podría ser el asociado a un cliente de un hotel, o quizá un apunte contable, o el resultado de fichar un libro en una biblioteca. Vamos a construir un pequeño programa que se basa en la estructura siguiente:
struct Registro {
char modelo[10];
int fecha;
char fabricante[20];
float peso;
};
Nuestro objetivo es construir un programa dotado de las opciones siguientes:
-
Crear un archivo nuevo.
-
Abrir un archivo existente.
-
Añadir registros al archivo abierto.
-
Salir de programa.
Los registros añadidos se rellenarán previamente a través del teclado.
Evidentemente, la tercera opción es la que nos permite "dar altas". El programa es como sigue:
Los resultados de una ejecución de este programa son los siguientes:
Aquí hay que añadir datos de algún coche actual, digamos Volkswagen o Audi.
Bajas
.
Este es el concepto inverso al anterior: eliminar un registro. La eliminación de registros conlleva ciertas dificultades, derivados de la forma en que están construidos los archivos de disco. Esos problemas son análogos a los que aparecen al "eliminar" un registro en una lista de estructuras basada en RAM. Ciertamente, si se elimina un registro en una lista no lineal dinámica, el problema no es problema: basta emplear las técnicas oportunas
(q.v.)
y el resultado será una lista carente de ese registro, sin que aparezca una fuga de memoria. Sin embargo, si se elimina un registro en una lista lineal (dinámica o no), el resultado será un "hueco", que luego podrá ocuparse o no, pero que de momento supone una cierta cantidad de memoria que no se está utilizando y no se puede reutilizar. Esto mismo va a suceder en los archivos de disco, que a fin de cuentas son lineales desde el punto de vista lógico, aunque sean no lineales desde el punto de vista físico.
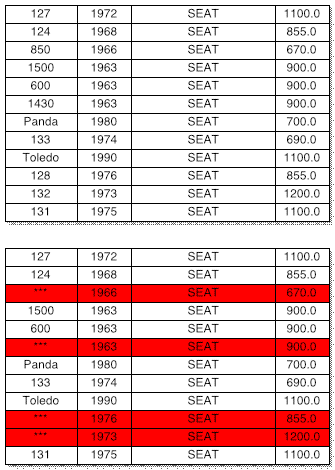
Entonces, ¿cómo se "borra" un registro en una base de datos basada en disco? La solución que suele emplearse tiene dos etapas. En primer lugar, se marca el registro en cuestión, insertando un cierto valor en algún campo destinado al efecto. Por ejemplo, si consideramos la base de datos cuyos registros se describen en la sección anterior, se podrían insertar tres asteriscos en el campo de modelo, o cualquier otra cadena que no pueda correspondera un modelo. Esto permite saber que el registro en cuestión puede reutilizarse, según puede verse en la imagen, marcado en rojo. Pero este procedimiento da lugar a la aparición de "huecos" en la base de datos, y esto produce varios inconvenientes:
-
El espacio ocupado por la base de datos no se reduce al descartar registros.
-
El procesamiento de información se va volviendo más lento a medida que se utiliza el archivo, porque cada vez hay más registros que es preciso examinar para descartarlos directamente.
-
No es posible mantener correctamente ordenada la base de datos; esto es muy problemático pues los métodos de búsqueda binaria pueden acelerar mucho el procesamiento de información. Téngase en cuenta que si ser ordenan la base de datos seguirán apareciendo registros inútiles.
La solución de este problema consiste en aplicar un proceso de compactación ("
crunch
"), que no es otro que eliminar los registros marcados como eliminados. Esto puede hacerse de varias maneras:
-
Compactación "in situ"
. Consiste en trasladar registros válidos a las posiciones del archivo ocupadas por registros vacíos, tomando los registros válidos del final del archivo. De este modo, cuando ya no quedan registros vacíos, se puede truncar el archivo después del último registro utilizado.
-
Compactación "in situ" en RAM
. Este procedimiento consiste en cargar en RAM todos los registros del archivo considerado, para después cerrar el archivo y escribir sobre él, pero únicamente los registros no vacíos. Este procedimiento tiene la desventaja de que puede no ser realizable si no se dispone de RAM suficiente, y supone un grave riesgo de pérdida de datos si la nueva versión del archivo no llegara a crearse correctamente. Salvo en el caso de archivos fáciles de reconstruir, no debe emplearse este método.
-
Generación de un nuevo archivo por copia
. Este procedimiento, más sencillo, consiste en crear un nuevo archivo que sólo contendrá registros válidos (leyendo registros del archivo original y copiando únicamente los registros válidos en el nuevo). Finalmente, se descarta el archivo original. Este procedimiento posee una desventaja importante: hay un momento en que coexisten ambas versiones (vieja y nueva) del archivo, con el consiguiente consumo temporal de espacio en disco.
Sea cual fuere el método empleado, el resultado final debe ser una base de datos perfectamente correcta, en la cual se habrá dado la baja al registro deseado. Téngase en cuenta, desde luego, que será preciso ofrecer al usuario algún método para seleccionar exactamente el registro o registros que desea dar de baja. Téngase en cuenta también la posibilidad de que existan registros duplicados: ¿cuál hay que eliminar? Este problema se resuelve añadiendo a todos los registros un campo de clave, que los identificará de forma exclusiva, y tiene aplicación tanto en las bajas como en el uso de índices.
Ejercicio
.- Construir un programa adecuado para eliminar registros en una base de datos construida con el programa de la sección anterior. El programa debe mostrar al usuario el contenido de la base de datos, para después admitir la clave del registro que se quiere dar de baja. Se utilizará el método de compactación en RAM.
Modificaciones.
Considérese una base de datos que contiene el inventario de un almacén. Un inventario es una colección de registros, cada uno de los cuales contendrá campos similares a los siguientes:
-
Clave de producto
-
Número de unidades
-
Precio unitario
Los inventarios son archivos de contenido muy cambiante: diariamente, el almacen recibe mercancías y sirve pedidos, lo cual implica la necesidad de modificar el contenido de los registros correspondientes a las múltiples referencias que constituyen el negocio de la empresa. Como se comprenderá, hemos simplificado mucho el contenido del registro, que posiblemente contendría campos para descuentos por volumen, rotación del producto, estimación de ventas par el mes actual, etc. Con todo, vamos a construir un programa de inventario para un almacén juguetes. El almacen sirve, entre otros artículos, miniaturas de coches como los descritos en la base de datos empleada en la sección anterior. El campo de modelo servirá como clave de producto; de este modo, no es preciso repetir toda la información en ambos archivos.
Ejercicio
.- Construir un programa que permita introducir modificaciones en el archivo de inventario de un almacén basado en las especificaciones anteriores. El programa deberá permitir hacer modificaciones en la base de modelos y en el inventario.
El programa podría adoptar la forma siguiente:
Los resultados de ejecutar este programa con como sigue:
Comentarios
.-
Informes
.
Esta es la parte más importante de una base de datos: la extracción de información. No debe pensarse que esto se limita a recuperar información almacenada anteriormente; antes bien, la faceta fundamental es precisamente obtener nuevas informaciones basadas en los datos disponibles. Por ejemplo, y refiriéndonos a los ejemplos anteriores, el usuario del programa puede solicitar la relación de productos en falta, esto es, la relación de productos tales que el número de unidades disponibles es 0. O puede solicitarse una relación de todos los artículos cuyos preciso estén entre dos dados, y de los cuales se disponga de un
stock
de valor superior a cierta cifra.
En general, un informe es una colección de informaciones que se caracterizan por haber sido extraídas de registros tales que sus campos satisfacen ciertos criterios. Estos criterios pueden ser únicos o múltiples, y la especificación de criterios puede resultar compleja.
Ejercicio
.- Construir un programa adecuado para generar informes a partir de las bases de datos creadas en las secciones anteriores. El programa permitirá crear informes por cualquier campo de cualquiera de estas bases de datos.
El problema del tratamiento de bases de datos es uno de los temás más importantes de la informática de todos los tiempos. Los rudimentos planteados aquí alcanzan su verdadera dimensión en lenguajes como SQL, creados para el manejo y consulta de bases de datos. Téngase en cuenta la posibilidad de permitir que el usuario proporcione directamente secuencias de operaciones al programa; se tendrá entonces la posibilidad de construir "programas" que gestionen una base de datos. Esta es precisamente la idea que subyace a muchos gestores modernos de bases de datos. Véase, por ejemplo, esta
página
.
Lectura en bloque y por registros.
El tiempo necesario para cargar una información en RAM es tanto mayor cuanto mayor sea el número de accesos a disco necesarios para efectuar el trasvase. Entonces el procedimiento ideal para cargar una base de datos en RAM es aquel que emplea una sóla operación de lectura.
La memoria RAM es un recurso muy valioso de la UCP. Un programa es tanto más eficiente cuanto menor sea su consumo de RAM, pues permitirá cargar en memoria más programas y dar servicio, por tanto, a más solicitudes de los usuarios.
Las dos afirmaciones anteriores son
ciertas pero contrapuestas
, como es habitual en el mundo de la ingeniería del software. En su aplicación al manejo de archivos se tienen dos necesidades: la de velocidad, que se satisface cargando todos los archivos en RAM, y la de bajo consumo de memoria, que se satisface cargando en RAM registros individuales. La técnica que se deba seguir dependerá, en cada caso, del volumen de información y de la RAM disponible. Una aproximación razonable consiste en estimar la cantidad de RAM que consume el programa, según lo indicado por el sistema operativo, y adaptar la cantidad de información residente en RAM a las posibilidades del ordenador que vaya a emplearse.
Ejercicios propuestos
-
Ejercicio 1004r01.-
Emplear el método de compactación por copia en un archivo nuevo para eliminar registros en una base de datos.
-
Ejercicio 1004r02
.-Emplear el método de compactación "in situ" para eliminar registros en una base de datos.
-
Ejercicio 1004r03
.-Una base de datos dispone de un campo de clave basado en un índice alfanumérico. Se pide construir un programa que calcule una tabla de claves de índices, ordene esa tabla por el campo de claves y reescriba el archivo ya ordenado (en otro archivo).
-
Ejercicio 1004r04
.-Una base de datos dispone de un campo de clave basado en un índice alfanumérico. Se pide construir un programa que calcule una tabla de claves de índices, ordene esa tabla por el campo de claves y reescriba el archivo ya ordenado (
in situ
).
-
Ejercicio 1004r05
.-Construir un programa adecuado para generar matrices 50x50, formadas por números aleatorios. El programa deberá ofrecer al usuario la posibilidad de almacenar matrices en disco, leer matrices, sumar matrices y multiplicar matrices.
-
Ejercicio 1004r06
.- Se dispone de un archivo binario que contiene un número indeterminado de registros. Los registros corresponden a una estructura de la forma:
struct Volumen {
char autor[40];
char titulo[40];
char editorial[20];
int fecha;
};Se pide construir un programa que traduzca esta base de datos de formato binario a formato encolumnado o delimitado, a voluntad del usuario.
-
Ejercicio 1004r07
.- Construir un programa adecuado para realizar, altas, bajas, informes y modificaciones en una base de datos basada en la estructura descrita al principio de esta sección. Se considera que el archivo es de tipo binario homogéneo.
-
Ejercicio 1004r08
.- Analizar el problema asociado al manejo de un hotel y desarrollar estructuras de datos que permitan crear un programa de base de datos adecuado para el tratamiento del mismo. Se recomienda construir un archivo de clientes y una colección de archivos históricos de ocupación del hotel (un archivo por día, con nombre de archivo igual a la fecha).
-
Ejercicio 1004r09
.- Se dispone de una base de datos almacenada en un archivo de disco de formato binario. Los registros son estructuras de la forma siguiente:
struct Registro {
char nombre[40];
int edad;
float talla;
};
Se pide construir un programa adecuado para crear esta base de datos. El programa asignará valores iniciales a todos los registros (en número indicado por el usuario) y los almacenará en disco, con el mencionado formato binario.
-
Ejercicio 1004r10
.- Considérese el archivo binario creado en el ejercicio anterior. Se pide construir un programa que lea registro por registro y almacene en otro archivo aquellos registros tales que el campo de edad se encuentre entre dos valores dados por el usuario. Los nombres de ambos archivos serán suministrados por el usuario.
-
Ejercicio 1004r11
.- Considérese el archivo binario creado en el Ejercicio 1004r09. Se pide construir un programa que lea la información residente en el archivo y busque todos los registros en que la edad sea menor que un cierto valor y la talla mayor que otro; ambos datos serán suministrados por el usuario. El programa debe almacenar en disco los registros hallados, también con formato binario, pero por orden inverso al de su aparición en el archivo original.