ARCHIVOS
 Generalidades
Generalidades
En primera aproximación, la potencia de una computadora viene determinada dos factores primordiales:
-
La RAM disponible, que determina la cantidad de datos y programas que podrá ejecutar en tiempo compartido
-
Y la potencia de su procesador, que determina la velocidad con que responderá a las solicitudes de los programas.
Este panorama es real, pero no contempla un detalle fundamental: ¿de dónde proviene la información (tanto datos como programas)? Podría pensarse en una conexión de red, y el resultado son las "diskless workstations", estaciones de trabajo que toman su información de otras máquinas a través de la red. Pero esto solo traslada el problema: ¿de dónde proviene la información existente en esas otras máquinas? La respuesta es, claramente, el
subsistema de almacenamiento masivo
, que se caracteriza por un coste por megabyte muy reducido en comparación con los precios de RAM, y por ser permanente: aun cuando se corte la alimentación del subistema, su contenido permanecerá inalterado, a diferencia de la RAM, cuyo contenido desaparece con la alimentación.
Concretando, el subsistema de memoria permanente se organiza de tal modo que las aplicaciones y los datos se almacenan en bloques llamados archivos. Esos archivos tienen un nombre, que se utiliza para accede a ellos. Como el número de archivos suele ser elevado, es preciso organizarlos, y de eso se encarga el sistema de archivos empleado.
El manejo de archivos plantea dificultades similares a las que aparecen a la hora de leer información del teclado o imprimir información en pantalla. A diferencia de la pantalla, un archivo no tiene "anchura máxima", y se pueden formar "líneas" tan largas como se desee. Los archivos, a diferencia de las hojas de papel en que uno tiende a pensar cuando se habla de información escrita, no tienen "ancho", ni "largo"; ni siquiera existe el concepto de línea o de hoja. Sólo hay, por así decir, una línea de información tan larga como se quiera. Será responsabilidad de la aplicación que lea ese archivo mostrarlo con formato "humano", esto es, en la forma de líneas, párrafos y páginas que estamos acostumbrados a manejar.
Habida cuenta de que no hay restricciones en lo tocante a escritura, escribir va a ser una tarea "sencilla": el archivo lo admite todo. Los problemas vienen, sin embargo, a la hora de leer lo escrito. Leer información de un archivo conlleva dos tareas:
-
Traducir la información leída a un formato procesable en la computadora. Esto exige, por ejemplo, traducir la información numérica del formato de texto empleado al formato binario correspondiente.
-
Insertar ésa información en las estructuras de datos creadas al efecto, para su posterior procesamiento. Por ejemplo, los registros de una base de datos almacenada en disco deben cargarse en las oportunas estructuras de datos creadas en memoria.
Cuanto más regular y sencillo sea el formato empleado al escribir, más fácil resultará la lectura. En todo caso, será preciso definir y seguir una convención para el almacenamiento y recuperación de datos en disco: a esto se le da el nombre de
formato del archivo
. Una vez conocido el formato, es posible realizar la lectura.
Definición de archivo.
Desde el punto de vista de C, un archivo es una colección numerada y ordenada de bytes. Es posible leer o escribir a partir de cualquiera de las posiciones de memoria de que consta el archivo, y también es posible añadir información al archivo o imponer un fin de archivo en alguna posición anterior a su situación actual (salvo archivos vacíos, claro).
El nombre del archivo puede emplearse para indicar al sistema operativo, y a las aplicaciones, la forma en que se ha organizado el contenido del archivo. Según su contenido, existen dos tipos genéricos de archivos:
-
Archivos de texto
, caracterizados por contener únicamente caracteres imprimibles.
-
Archivos binarios
, que no poseen restricciones respecto a su contenido.
Definición de sistema de archivos
Un sistema de archivos (
filesystem
en la literatura) es un sistema de software (un conjunto de convenciones de denominación, almacenamiento y acceso) que permite almacenar y recuperar información en algún medio. Esta definición, muy general, se refiere a todos los programas que permiten que una computadora almacene información (cintas, discos flexibles, discos rígidos, memoria RAM) de tal modo que esa información se puede recuperar a voluntad del usuario. El sistema se encarga de mantener un directorio formado por bloques de información a los que se conoce con el nombre de archivos. Estos archivos poseen un nombre y suelen organizarse en directorios, que son el equivalente de carpetas en las cuales se pueden almacenar otros archivos o directorios. Se dice entonces que los sistemas de archivos tienen una estructura arborescente, con una "raíz" que es el directorio de entrada al sistema y (posiblemente) múltiples ramificaciones que podrán ser, a su vez, archivos o directorios. Los sistemas de archivos dependen del sistema operativo empleado; no es infrecuente hallar sistemas operativos que admiten múltiples sistemas de archivos.
Archivos de texto
Los ficheros de este tipo se utilizan fundamentalmente:
-
Para emisión de informes sencillos. Tal sería el caso de informes encolumnados.
-
Para intercambio de información entre programas. En general, los programas disponen de un módulo de importación que les permite leer archivos de formato texto. Basta disponer de un módulode importación y otro de exportación para garantizar que el programa nunca esté incomunicado.
-
Para generación de informes complejos. Téngase en cuenta que un archivo RTF es un archivo de texto. Nada impide que un programa escriba (en formato texto) el contenido de un archivo RTF, al que se asignará un nombre acabado en
.rtf
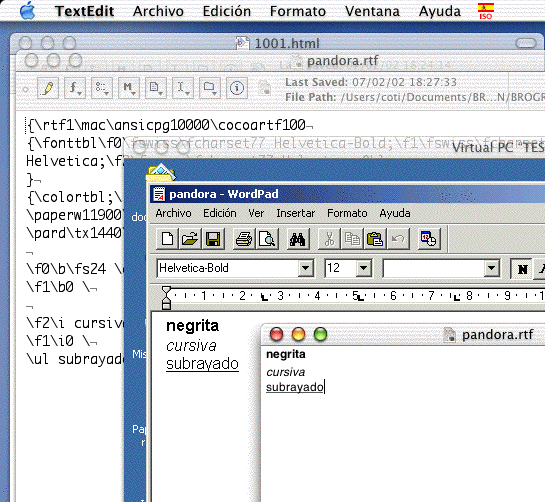
. El contenido de un archivo RTF se puede investigar muy bien guardando un archivo sencillo desde un editor de textos y analizando su contenido. En la imagen siguiente puede verse un sencillo pero interesante ejemplo. Esta imagen es un fragmento de un volcado de pantalla. En primer plano, la aplicación TextEdit (ejecutándose en Unix, Mac OS X®) muestra el contenido del archivo
pandora.rtf
, de formato texto. En segundo plano, la aplicación WordPad, ejecutándose bajo Windows 2000®, muestra el contenido de ese mismo archivo (Virtual PC® está compartiendo el sistema de archivos de Mac OS). En tercer plano, se muestra el contenido de
pandora.rtf
en formato texto, sin interpretación. Dado lo breve de este archivo, está claro que resulta viable emitir informes en formato
rtf
, con toda la expresividad de este formato. El nombre seleccionado para el archivo,
pandora.rtf
, es apropiado, pues verdaderamente el uso de
RTF
desde C supone la posibilidad de generar complejos informes multiplataforma.
Retomando el tema del formato, del que hablábamos más arriba, los archivos de texto requieren especial cuidado a la hora de escribir y leer. Los lectores humanos tienen capacidades contextuales pero los ordenadores se atienen exclusivamente a la información textual. Por tanto, se emplean formatos de archivo como los que se describen a continuación. Utilizaremos como ejemplo el volcado a disco de una colección de estructuras como la siguiente:
struct Registro {
char modelo[10];
int fecha;
char fabricante[20];
float peso;
};
-
Formato de un campo por línea. Este es, posiblemente, el formato de texto más sencillo que se puede emplear. Consiste en descomponer cada registro en campos, y escribir cada campo en una línea. Después será sencillo leer líneas completas, sabiendo que cada una es un campo, y asignar el valor leído al campo correspondiente de la estructura de datos preparada al efecto. Este formato no es demasiado legible para seres humanos (es mucho más comprensible el formato tabular), pero resulta casi trivial de implementar. Recuérdese que en nùmeros de coma flotante puede haber pérdida de precisión si no se especifica el uso de un formato de texto de precisión suficiente. Un ejemplo de volcado con este formato sería:
-
Formato delimitado por tabuladores. Este formato consiste en escribir un registro por línea, y
newline
al final de cada línea. Los campos se separan mediante un carácter delimitador, que será cualquier carácter que no pueda formar parte del campo, para evitar incongruencias. Suelen emplearse los asteriscos y los tabuladores. Una buena aproximación para el uso de archivos de formato de limitado consiste en escribir una primera línea que especifica el delimitador y los tipos de los campos, y una segunda línea que especifica los nombres de los campos (separándolos mediante el delimitador). De este modo al leer se dispone de toda la información.
-
Formato encolumnado. Este formato es el que resulta de traducir "literalmente" los campos a formato de texto. Concretamente, los campos de formato alfanumérico (cadenas de caracteres) se escriben sin traducción, rellenando el espacio sobrante, si lo hay, mediante espacios en blanco, hasta llegar a la longitud reservada para el campo en el registro. Los campos numéricos se traducen al formato de texto y se les asigna una longitud constante, adecuada para no perder precisión; si es menester, se rellena el espacio sobrante mediante espacios en blanco. Los campos que son caracteres individuales o bytes se traducen a texto y se escriben sin más transformación. El resultado final es que cada registro ocupa una línea, y todas las líneas tienen igual longitud (puesto que los campos tienen igual longitud en todas las líneas). Obsérvese que no hay separación entre campos; dados dos campos sucesivos, el último carácter del primer campo es justamente el anterior al primer carácter del segundo. Este formato tabular resulta de lectura cómoda (para el usuario) y se usa con relativa frecuencia. El ordenador tiene que hacer un cierto esfuerzo a la hora de leer, pero todo puede solucionarse empleando un formato de lectura análogo al empleado en la escritura.
Véase a continuación un ejemplo de los tres formatos mencionados:
/*Formato encolumnado*/
1271972SEAT1100.0
1241968SEAT 855.0
8501966SEAT 670.0
15001963SEAT 900.0
/*Formato delimitado por asteriscos*/
127*1972*SEAT*1100.000000
124*1968*SEAT*855.000000
850*1966*SEAT*670.000000
1500*1963*SEAT*900.000000
/*Formato de un campo por línea*/
127
1972
SEAT
1100.000000
124
1968
SEAT
855.000000
850
1966
SEAT
670.000000
1500
1963
SEAT
900.000000
Formato binario
Si se elimina la restricción propia de los archivos de texto, que sólo admiten caracteres imprimibles, es posible construir archivos que contengan cualquier byte. En este sentido hay que precisar que a efectos de los archivos, el formato binario y el formato de texto son una misma cosa. En un archivo se puede leer con formato o sin él, y se puede escribir con formato o sin él, pero el archivo, en sí, no implica transformación. Son las sentencias empleadas las que causan uno u otro formato.
El formato "binario", más general, se emplea en las siguientes ocasiones:
-
Ficheros ejecutables. Los programas, escritos ya en lenguaje máquina listo para su ejecución, se guardan en disco como "imágenes" del contenido de la zona de memoria en que se ejecutarán una vez cargados.
-
Almacenamiento de datos. Los datos numéricos de todo tipo se benefician notablemente de la carencia de traducción:
-
Ocupan menos, y siempre lo mismo (el número de bytes reservado para las variables de este tipo).
-
No pierden nunca precisión, porque se almacenan todos sus bits.
-
Se leen y se escriben con la mayor rapidez posible, porque no es necesario efectuar una traducción para leer ni para escribir.
Por estas razones, el almacenamiento de datos numéricos de todo tipo (tablas, sonido, video) se hace siempre con este formato, en lugar de efectuar una traducción algún formato de texto.
Al igual que sucede con los formatos de texto, es imprescindible conocer el formato con que se escriben los ficheros binarios si se desea interpretar su contenido. En este sentido, es muy frecuente encontrar archivos de formato binario que contienen colecciones de estrucuras idénticas (registros). La lectura o escritura en estos archivos se hará normalmente en términos de estructuras del tipo empleado en su creación; el lenguaje mantiene, como se estudiará al describir la función
fseek()
, un "cursor" que señala el lugar en que se leerá o escribirá en la próxima operación. La posición del cursor es controlable por programa. De este modo, se puede leer o escribir cualquier registro deseado.
De forma similar a lo que ocurre en los archivos de texto, conviene dotar a los archivos binarios de un encabezado, que describe la organización de su contenido. Entonces el programa lee el encabezado, construye en memoria la oportuna estructura de datos, y después va trasladando el contenido del disco a memoria. Evidentemente, este encabezado es crucial para la interpretación del archivo, y por esta razón se suele duplicar al final del mismo. De este modo, cabe esperar que si se daña una de las copias la otra quede intacta y sea posible reconstruir el archivo, tarea que de otro modo será muy laboriosa. (Se puede incluir un marcador de fin de registro entre bloques de información, con objeto de facilitar la recuperación.)
¿Qué contiene un archivo binario?
La respuesta se puede obtener de manera sencilla mediante una herramienta como
hexdump
, que suele estar presente en todos los sistemas basados en Unix. Como ejemplo, vamos a considerar el archivo binario que genera el programa de base de datos estudiado en una sección anterior. Vamos a crear algunos registros, según se ve en la imagen, y después analizaremos el contenido del archivo binario asociado a esta pareja de registros. La imagen a que nos referimos es la siguiente:
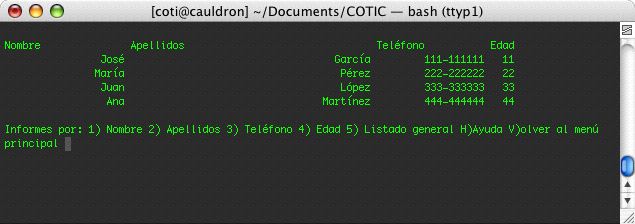
Como puede verse, la base de datos contiene cuatro registros, que se almacenan en
archivo.dat
.
El resultado de aplicar
hexdump
a
archivo.dat
es el siguiente:
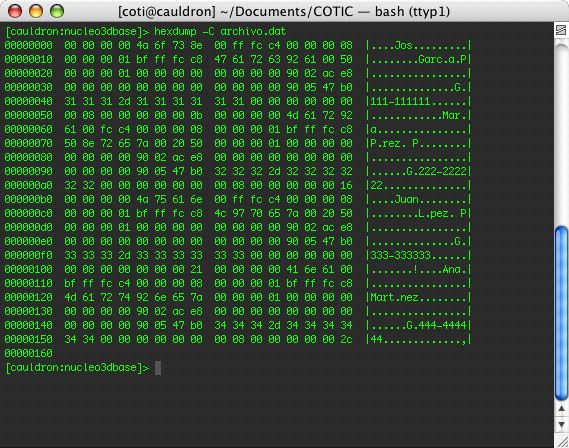
A primera vista (columnas de la izquierda) el resultado es un galimatías sin sentido. Pero la columna de la derecha permite apreciar fácilmente los nombres y apellidos, así como los teléfonos. Se puede apreciar que el código hexadecimal correspondiente al número 1 es el
31
, y por tanto los códigos hexadecimales
32
y
33
corresponden a 2 y 3 respectivamente. La edad, sin embargo, resulta menos comprensible. Esto se debe a que se trata de un
int
, y como tal está codificado en formato binario, ocupando 4 bytes.
Como ejercicio, se sugiere al lector cambiar la posición de los campos, de modo que el nombre sea el primer campo y el apellido sea el último. Luego puede resultar instructivo insertar nombres y apellidos formados por una serie como
AAAA...A
y
ZZZZ..Z
. ¿Se aprecia ahora mejor el principio y el final de los campos? ¿Se aprecia la presencia del número 0 (el carácter '\0') al final de las cadenas? El ejemplo mostrado en la imagen permite ver esto claramente: en verdad, el formato interno de las cadenas en C tiene un marcador
0
al final.
Lectura por bloques y velocidad de transmisión.
Este es un problema interesante, que puede suponer notables ganancias de rendimiento si se emplean los métodos adecuados. Como se recordará, el tiempo requerido para acceder a la información residente en un disco es la suma de dos factores:
-
Tiempo de acceso, que es el tiempo necesario para que las cabezas de lectura y escritura estén sobre la pista deseada. Téngase en cuenta que este es un caso clarísimo de oscilación: la cabeza "busca" su posición, pero tarda un tiempo en alcanzarla de forma estable. Esto es lo que se denomina tiempo de acceso, y se mide en milisegundos (alrededor de 10 ms es un tiempo de acceso razonable).
-
Tempo de latencia, que es el tiempo que transcurre hasta que el sector deseado pasa precisamente por debajo de la cabeza de lectura y escritura. Cuanto más grande físicamente sea el disco (cuanto mayor sea su radio), mayor será el tiempo de latencia. Cuanto más deprisa gire el disco, menor será este tiempo.
La cantidad de tiempo que se tarda en cargar una información en memoria depende del número de accesos a disco que es preciso realizar. Evidentemente, cuanto mayor sea el número de veces que se acceda a disco, mayor será el tiempo invertido. Es complicado conocer a priori el número real de accesos a disco necesarios, porque los subsistemas de disco hacen uso de un búfer en que se cargan múltiples bloques por acceso (al margen de lo solicitado), y lo mismo ocurre en el ordenador, pues el sistema operativo también hace uso de espacios de memoria intermedia par reducir el número de accesos. Por esta razón, suele ser muy rápido acceder a pequeños bloques de memoria, que residirán en el búfer del disco y también en el búfer del ordenador. Cuando se desborda la capacidad de estas memorias intermedias, cae el rendimiento, tanto en lectura como en escritura. En estas circunstancias aparece el "verdadero" comportamiento del disco, y la velocidad de acceso es tanto mayor cuando menor sea el número de accesos. Dicho de otro modo, se obtienen mejores velocidades cuanto mayor es el tamaño del bloque. Téngase en cuenta que, si el archivo no está fragmentado, una vez situadas las cabezas sólo queda esperar que la información vaya pasando por debajo de ellas, luego se obtiene velocidades de transferencia similares al máximo teórico. Cuanto mayor sea la fragmentación, desde luego, peor será el rendimiento, pues incurriremos en los costes de acceso para cada fragmento del archivo, irremediablemente.